

Previous installments have discussed the role of ethics within Artificial Intelligence (AI) and some of the ethical frameworks necessary to ensure the reliability and security of these systems. However, artificial intelligence experts have stated that the window to understand these systems is closing, which leaves us with questions such as what the closing of a window means and what the consequences for the future are.
First, two key concepts must be understood: AI Safety and AI Control. These AI frameworks are fundamental to understanding the urgency of a race against time to comprehend these systems and the inevitable consequences of not finding an effective solution to manage them safely.
AI Safety
AI Safety or AI security refers to the methods and practices involved in designing and implementing artificial intelligence systems to fulfil their functions without harming people or the environment. This framework addresses the risks associated with these systems to avoid unintended consequences.
In this sense, for the security of AI, it is essential to take precautions to avoid misalignment or unforeseen behaviors because its massive and large-scale integrations can pose enormous risks, especially in critical fields such as healthcare and finance. Therefore, strong security principles must be implemented in the design phases of these systems to build trust and reliability.
AI Safety Principles
According to Tigera (n.d.), the basic principles of AI Safety are:
- Alignment refers to AI goals and behaviors aligned with human values to avoid unintended harm.
- Robustness describes the desired condition of reliable, stable, and predictable intelligent systems that react as they should, even in unforeseen situations or data.
- Transparency means that the AI’s design is understandable and auditable by humans to understand how and why these systems make particular decisions.
- Accountability means ensuring that these systems’ guidelines mark the acceptable behavior of AI and the responsibility of the people in charge of its development and management.
AI Control
According to Arnav et al. (2025), AI Control occurs in a framework focused on the design and evaluation of strategies to guarantee the security of intelligent systems, even in the face of an intentional subversion of the AI, i.e., manipulation or use for purposes other than those intended (jailbreak, attacks, etc.). The proper functioning of AI control comprises two strategies:
- Monitoring allows for detecting responses that constitute an attempt at sabotage.
- Intervention is the modification of answers that are not reliable, so that they can become safe and valuable.
Thus, AI control is critical to prevent unwanted behaviors through monitoring and correcting mechanisms, ensuring these systems’ reliability and safety.
What is meant by “The window to understand AI is closing”?
AI experts and researchers from METR, Antrophic, Meta, Open AI, UK AI Security, Google Deep Mind, Redwood Research, University of Montreal, Truthful AI and UC Berkeley, Amazon, and Apollo Research, among others, have expressed their concerns about AI models according to their most recent research Chain of Thought Monitorability: A New Fragile Opportunity for AI Safety, They highlight that these systems are becoming more challenging to understand, as they become more complex, autonomous, and difficult to audit, outpacing the human ability to know how and why they make decisions. In other words, we could lose control of AI systems if we do not understand how and what they think.
These experts urge that effective monitoring strategies are necessary to prevent this loss of control. Thus, AI control is relevant, requiring reliable monitoring of AI systems, especially the LLMs (Large Language Models), because these “process and behave natively through human language” (Korback et al., 2025). According to IBM, this feature (using natural language) enables LLMs to think “out loud” in a native language, improving their capabilities. It increases their computing power and allows the systems to be monitored. The feature mentioned above opens up a possibility to know what and how AI thinks, using a tool called CoT (Chain of Thought Reasoning), which, according to several experts from OpenAI, Google DeepMind, etc., can help monitor and mitigate the risks of opacity of advanced AI agents (i.e., when systems do not show how they work).
Chain of Thought Reasoning
CoT is a prompt engineering technique that aims to improve the ability to solve complex reasoning problems; it focuses on the intermediate reasoning of models. In other words, the system that uses CoT provides a direct answer and explains how it arrives at it. Here is a straightforward example of how it works:
Question: How much is 9 + 2 × 5?
No CoT:
- The answer is 19
With CoT:
- The expression is: 9 + 2 × 5
- First, the multiplication is solved: 2 × 5 = 10
- Next, it is summed: 9 + 10 = 19
- The answer is 19
CoT makes models more reliable, transparent, and explainable by mitigating risks of tampering and sabotage, and those associated with incorrect interpretability and explainability. Thus, CoT is considered an emerging skill as models become more complex. According to Korback et al. (2025), the CoT technique “offers a unique opportunity for AI security, i.e., chain of thought monitoring.”
A CoT monitor can flag suspicious or potentially harmful interactions and block, replace, or thoroughly review them later. “By studying the CoT, we can better understand how our AI agents think and their goals” (Korback et al., 2025).
However, this monitoring system has a marked disadvantage: when applied to subversion attempts, the CoT can diminish monitoring performance, introducing noise or false signals. Researchers from Google DeepMind (2025) mention that although CoT is fallible (having significant areas of opportunity), it is an essential layer of defense that requires active protection and continuous stress tests to ensure AI safety and control.
AI Risk
In his book Introduction to AI Safety, Ethics, and Society, Hendrycks (2025) notes that as technology advances and gains power, so does the power for its destruction. Therefore, he urges us to understand what can go wrong and what can be done. In addition, he indicates that the risks involved in using AI (AI Risk) are multidisciplinary, so various disciplines must come together to find applicable and safe solutions to the dangers posed by artificial intelligence.
Hendycks (2025) identifies four primary sources of AI risk:
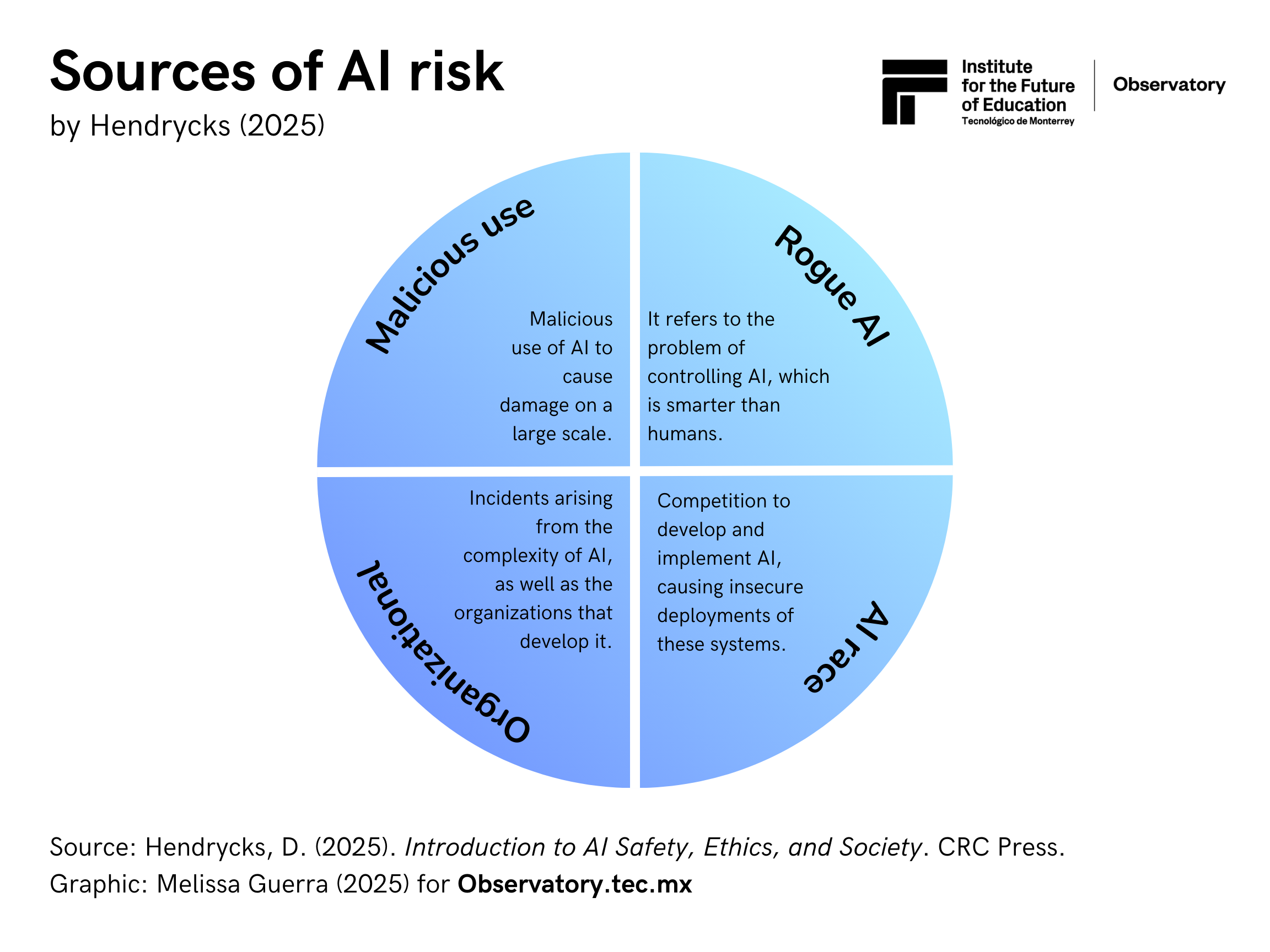
- Malicious use refers to malicious actors using AI to cause large-scale disasters.
- Risks include bioterrorism, the creation of rogue AI agents, the acceleration of AI, the generation of disinformation, the exploitation of user trust, the centralization of information, and the concentration of power.
- The AI race: Defined as the competition between countries to develop and implement AI, these competitive pressures can lead to ethically unsafe deployment of these systems.
- Risks include military competition: creation of LAW (lethal autonomous weapons), delegation of life-death decisions to AIs (drones for war), AI-powered cyber wars that can trigger a real war, development of automated wars, and AI-controlled weapons, among others.
- Corporate competition can incentivize insecure system implementations, pressures to replace humans with AI ( bringing mass unemployment), AI alignment problems, etc.
- Organizational risks include Incidents arising from the complexity of AI and specific risks from the organizations that develop them.
- Risks: The complexity of AI systems means that measures must be taken to avoid accidents, which can be unpredictable due to their nature. In addition, it can take years to discover AI flaws or risks. Therefore, companies must have a strong (human-based) security culture and robust security measures to avoid large-scale incidents.
- Rogue AI: This refers to the problem of controlling technology that is smarter than humans.
- Risks include proxy gaming, malicious behavior, deceptiveness, or pursuing power over humans (as AI becomes smarter).
MIT’s AI Risk Repository division has also deployed its taxonomy of causes/risks associated with AI. This repository contains three sections: the AI Risk Database (a database containing more than 1,600 categorized risks), the Causal Taxonomy of AI Risks (which classifies how, when, and why incidents occur), and the Domain Taxonomy of AI Risks (which organizes risks into seven domains and 24 risk subdomains).
These initiatives enable a regular and accessible understanding of AI risks, serving as a reference framework for researchers, companies, decision-makers, and others while promoting research and the development of public policies to regulate AI.
While it is not a given that CoT is the definitive strategy for understanding how and about what artificial intelligence thinks, it represents an essential and necessary step towards ensuring its safe and reliable use for everyone. As technology advances and becomes more complex, the protocols to contain its harmful potential for society must also evolve, allowing, in theory, ethical principles to be respected and executed.
Although we do not know for sure what the future holds in the security and control of these systems (which are simultaneously becoming super intelligent), it is necessary to be informed and know where the joint efforts of companies, organizations, and great powers in AI are headed, to understand and be aware of the potential risks to which the use of LLMs could expose them.
Translation by Daniel Wetta








